우선
티처블 머신으로 이미 만들어둔 텐서플로우의 모델과
같은 환경을 위해
아나콘다 프롬프트에서 같은 환경의 가상환경을 만든다
conda create -n tensor310 python=3.10 openssl numpy scipy matplotlib ipython scikit-learn pandas pillow jupyter seaborn
y를 입력하여 설치를 진행시킨다

가상환경이 만들어졌으니 VS코드를 실행시키자
우선 app.py를 만들어주고
시작의 기본인
import streamlit as st
def main():
pass
if __name__ == '__main__':
main()를 적어주고 시작하자
이제 pass부분을 지우고 본격적으로 시작하자
타이틀과 서브헤더를 적당히 지어주고
우리가 해야 할 일을 생각해보자
우리가 만들어둔 딥러닝 모델은
이미지파일을 input 받아서
그 이미지 파일이
11종류의 음식들로 분류를 예측하는 모델이다
그렇다면
1. 먼저 이미지파일을 업로드 받고
2. 받은 이미지파일을 모델을 사용하여 분류하자
1. 이미지 파일 업로드 받기
file = st.file_uploader('이미지 파일을 업로드 하세요.',type= ['jpg','jpeg','png','webp'])
if file is not None :
st.image(file)
.file_uploader를 통해
이미지 파일을 올려달라는 문구와 함께
타입을 이미지파일로 지정하고
그것을 file이라는 변수로 저장
이제 file이 존재한다면
file 이라는 이미지파일을 보여주자
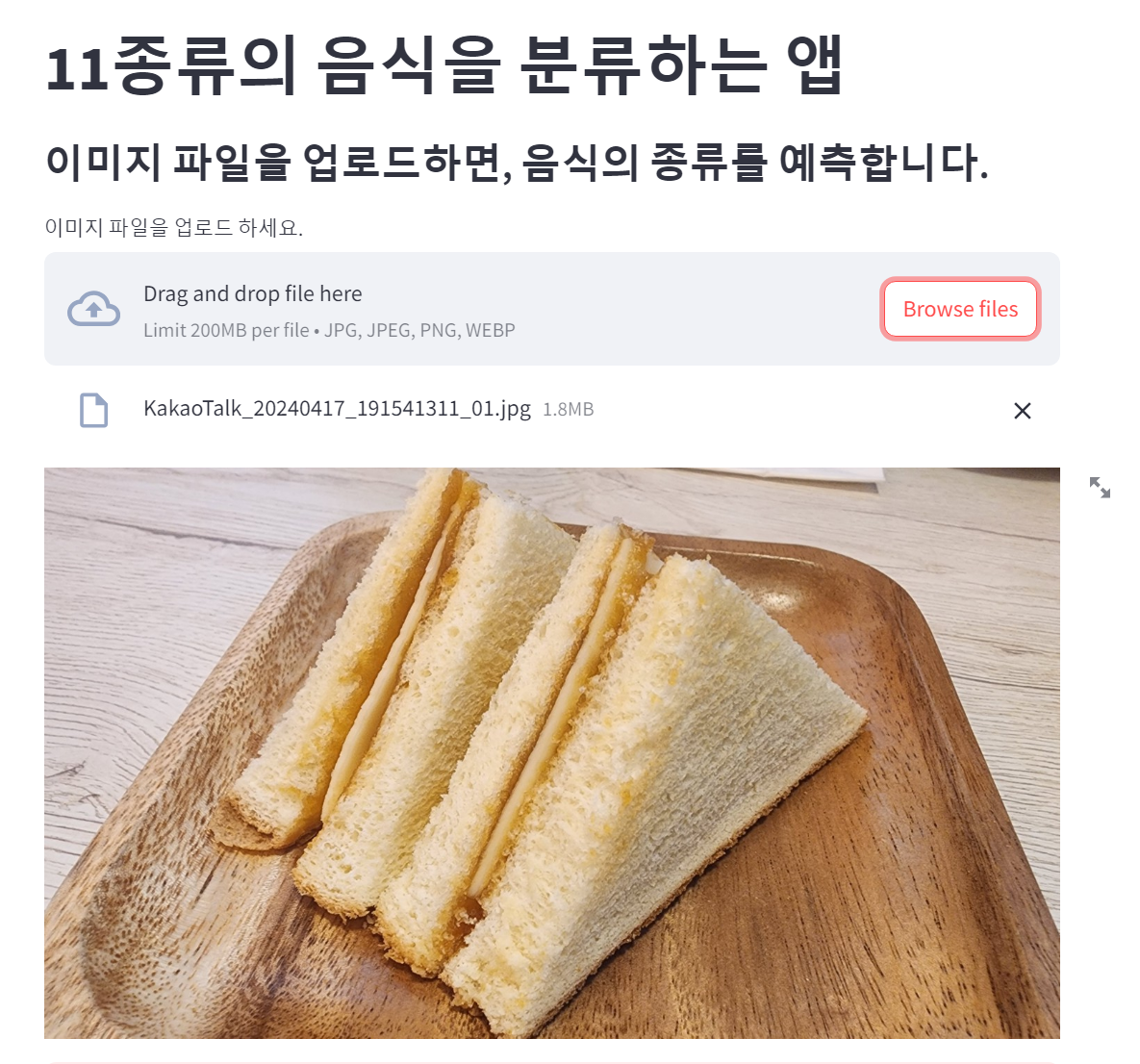
이렇게 말이다
다음은
티처블머신에서 모델을 저장할때 문구로 줬던
from keras.models import load_model # TensorFlow is required for Keras to work
from PIL import Image, ImageOps # Install pillow instead of PIL
import numpy as np
를 임포트해준뒤에
본문내용에
# Disable scientific notation for clarity
np.set_printoptions(suppress=True)
# Load the model
model = load_model("./model/keras_model.h5", compile=False)
# Load the labels
class_names = open("./model/labels.txt", "r", encoding='UTF8').readlines()
# Create the array of the right shape to feed into the keras model
# The 'length' or number of images you can put into the array is
# determined by the first position in the shape tuple, in this case 1
data = np.ndarray(shape=(1, 224, 224, 3), dtype=np.float32)
# Replace this with the path to your image
image = Image.open(file).convert("RGB")
# resizing the image to be at least 224x224 and then cropping from the center
size = (224, 224)
image = ImageOps.fit(image, size, Image.Resampling.LANCZOS)
# turn the image into a numpy array
image_array = np.asarray(image)
# Normalize the image
normalized_image_array = (image_array.astype(np.float32) / 127.5) - 1
# Load the image into the array
data[0] = normalized_image_array
# Predicts the model
prediction = model.predict(data)
index = np.argmax(prediction)
class_name = class_names[index]
confidence_score = prediction[0][index]
# Print prediction and confidence score
print("Class:", class_name[2:], end="")
print("Confidence Score:", confidence_score)
를 copy & paste하자
물론 모델의 저장경로 라던가
image 파일의 경로를 이제 업로드 받은 변수 file로 바꿔주는 등
약간의 수정이 필요하다
유저에게 보여주기 위한 멘트도 써주자
st.info('이 음식은 ' + str( round(confidence_score*100, ndigits=2) )+ '%의 확률로 ' + class_name[2:]+ ' 입니다')
라고 입력하여
모델이 인식한
가장 높은 확률의 음식종류를 알려주고
그냥 표기하면 0.784561323이런 식으로 나오게되니
사람이 보기 편하게 곱하기 100을 해준뒤에
소수점 2자리까지 반올림하여
78.46% 라고 알 수 있게 해준다

이런식으로 말이다
'Streamlit' 카테고리의 다른 글
| 스트림릿 다운로드버튼 download_button( ) (0) | 2024.05.02 |
|---|---|
| Streamlit - 탐색적 데이터 분석 방법.line_chart( ).area_chart( ).bar_chart( ).map( ) // Plotly_chart 의 px.pie( )px.bar( ) (0) | 2024.04.24 |
| Streamlit - 차트그리기 plt.figure( ) st.pyplot( ) (0) | 2024.04.24 |
| Streamlit - 파일 분리 앱 (0) | 2024.04.24 |
| Streamlit - 사이드바, 유저에게 파일 받기 (0) | 2024.04.24 |



