두 컬럼간의 관계를 차트로 나타내는 법
관계란? 보통 3가지 비례관계, 반비례관계, 아무 관계 없음
= 상관관계
두 컬럼간의 관계 => 배기량(displ)과 연비(comb)의 관계를 그래프로 확인
plt.scatter(data=df, x='displ', y='comb')
plt.show()
.scatter( )의 기본형태를 불러오자
data = 읽어올 데이터프레임, x축, y축을 설정해주면
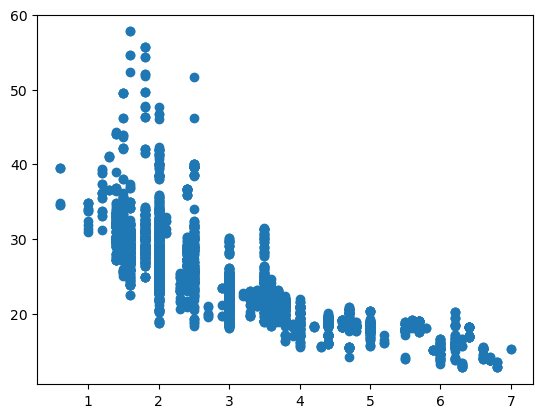
이런 모양이 나오는데 좀 부족하다
plt.scatter(data=df, x='displ', y='comb')
plt.title('Displ vs Comb')
plt.xlabel('Displacement')
plt.ylabel('Combined Fuel Eff (mpg)')
plt.show()
title( )로 그래프의 제목을
xlabel과ylabel 로 X축과 Y축의 이름을 지정해주자

두 데이터(컬럼)의 관계를 나타내는것 중
가장 많이 사용하는 것 : *상관관계분석*
상관계수를 확인하여, 비례/반비례/관계없음을 파악 가능
df[ [ 'displ','comb'] ].corr()
상관간계를 뜻하는
correlation를 의미하는
.corr( )를 사용하여
'displ' 과 'comb'의 상관관계를 알아보자

-1.0과 -0.7 사이, 강한 반비례 관계,
-0.7과 -0.3 사이, 뚜렷한 반비례 관계,
-0.3과 -0.1 사이, 약한 반비례 관계,
-0.1과 +0.1 사이, 거의 무시될 수 있는 선형관계 = 관계 없음 ,
+0.1과 +0.3 사이, 약한 비례 관계,
+0.3과 +0.7 사이, 뚜렷한 비례 관계,
+0.7과 +1.0 사이, 강한 비례 관계
즉,
-1에 가까울수록 반비례관계
1에 가까울수록 비례관계
0에 가까울수록 관련없다고 볼 수 있다
.regplot( )
regression 회귀라는 뜻이며
데이터에 fitting하는 선을 추가한다고 생각하자
위의 scatter( ) 대신 regplot( )을 이용해 만들어보자
sb.regplot(data=df, x='displ', y='comb')
plt.title('Displ vs Comb')
plt.xlabel('Displacement')
plt.ylabel('Combined Fuel Eff (mpg)')
plt.show()

다 똑같고 선이 하나 생겼는데
확실히 반비례 관계라는 것을 보여준다
sb.pairplot()
2개 이상의 상관관계들을 모두 그래프로 보여준다
sb.pairplot(data = df, vars=['displ','comb','co2'] )
plt.show()
C:\ProgramData\anaconda3\Lib\site-packages\seaborn\_oldcore.py:1119: FutureWarning: use_inf_as_na option is deprecated and will be removed in a future version. Convert inf values to NaN before operating instead.
with pd.option_context('mode.use_inf_as_na', True):
C:\ProgramData\anaconda3\Lib\site-packages\seaborn\_oldcore.py:1119: FutureWarning: use_inf_as_na option is deprecated and will be removed in a future version. Convert inf values to NaN before operating instead.
with pd.option_context('mode.use_inf_as_na', True):
C:\ProgramData\anaconda3\Lib\site-packages\seaborn\_oldcore.py:1119: FutureWarning: use_inf_as_na option is deprecated and will be removed in a future version. Convert inf values to NaN before operating instead.
with pd.option_context('mode.use_inf_as_na', True):
data = 읽어올 데이터프레임 을 적고
vars = 라는 [리스트]에 상관관계를 찾아 볼 콜럼들을 넣어주자
함수가 업데이트 되어 나중에 바뀐다는 메세지가 뜨지만
일단 지금은 정상작동 되니 그래프를 보도록 하자

누가 주체가 되느냐에 따라 x축 y축이 변경 되니 보기 편한것을 보도록 하자
Heat Map - 위의 산점도,산포도들은 점들의 밀도를 알 수 없기에 밀도를 알 수 있는 그래프를 한 번 보자
.hist2d
plt.hist2d(data=df, x='displ', y='comb')
plt.show()
우선 기본형으로 만들어보자
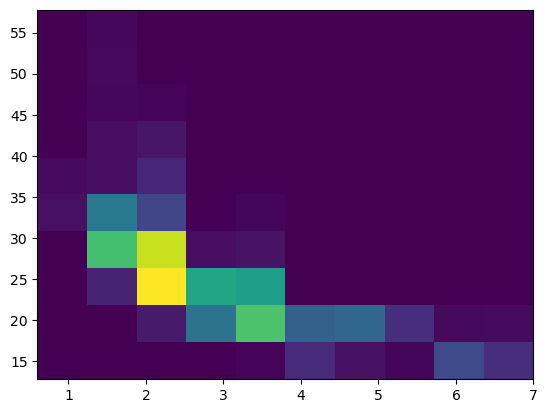
뭔가 보이긴 하는데 정확히 무엇인지 알아보기 힘들다 가공을 해주자
plt.hist2d(data=df, x='displ', y='comb', cmin=1, cmap='viridis_r', bins=20 )
plt.colorbar()
plt.title('배기량과 연비관계')
plt.xlabel('배기량')
plt.ylabel('연비(mpg)')
plt.show()
cmin은 이 숫자보다 작은 갯수를 가진 bin은 표시 되지 않게 하는 기능(배경을 하얗게)
cmap은 원하는 색상을 지정하는 기능
bins는 구간의 숫자
그리고 colorbar( ) 를 통해 각각의 색상이 무엇을 의미하는지
띄워주는 바를 나오게 해준다




