히스토그램은 구간을 설정하여 해당 구간에 데이터가 몇개인지 확인이 가능하다
그렇기에 데이터의 분포를 알 수 있다
히스토그램은 구간이 있는데 이 구간을 bin 이라고 하고
구간이 여러개라서 보통 복수형으로 bins 라고 한다
히스토그램은 똑같은 데이터를 가지고도
bin을 어떻게 설정하느냐에 따라 차트 모양이 달라져
해석을 달리 할 수 있다
가령

이런 숫자들의 데이터가 있다고 하면

이런식으로 구간을 6으로 묶은 그래프와
3으로 묶은 그래프에는
크게 보면 별 차이가 없지만
우측 그래프의 0~3구간과 15~18구간이 생각보다 비어있는것을
좌측 그래프에서는 알지 못 한다
이번엔 전의 포켓몬 데이터로 'speed' 콜럼을 통하여 데이터들이 어떻게 분포 되어있나 확인해보자
.hist( )
import matplotlib.pyplot as pltplt.hist( data=df, x='speed' )
plt.show()
일단 기본형의 히스토그램 생성은 hist( )를 통해 만들어진다
data= '가져올 데이터프레임', x= '데이터 분석할 콜럼' 을 넣어주자
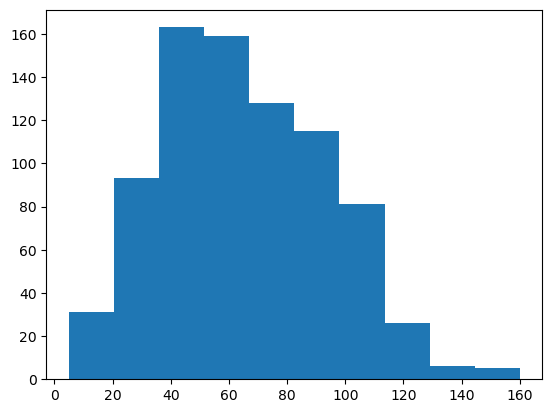
역시나 손이 많이 간다 우선은 너무 뭉쳐 있으니 좀 띄어주자
.rwidth=
plt.hist( data=df, x='speed', rwidth=0.8 )
plt.show()
.rwidth= 를 통해 떼어놓을 수 있겠다, 수치는 보기 좋게 띄어주면 된다

아까보다는 나아졌다 이번엔 구간의 bins들을 세분화 시켜보자
bins의 기본값은 10이다 bins = 20 을 입력하여 구간을 20으로 만들어주자
plt.hist( data=df, x='speed', rwidth=0.8, bins = 20 )
plt.show()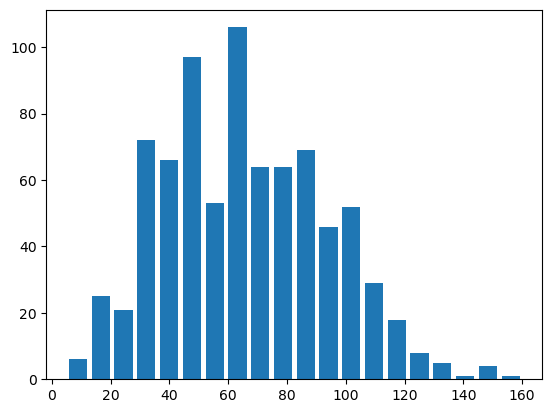
구간이 합쳐져있어 숨어있던 데이터들이 보이기 시작했다
보다 정확히 하기위해
bin의 범위를 재정리 하자
구간의 범위를 직접 설정 하기 위해
데이터의 최소값, 최대값을 알아보자
df['speed'].describe()
count 807.000000
mean 65.830235
std 27.736838
min 5.000000
25% 45.000000
50% 65.000000
75% 85.000000
max 160.000000
Name: speed, dtype: float64
최소값은 5
최대값은 160
my_bins = np.arange(5, 160+5, 5)
my_bins
array([ 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65,
70, 75, 80, 85, 90, 95, 100, 105, 110, 115, 120, 125, 130,
135, 140, 145, 150, 155, 160])
5부터 시작하고 5씩 커지는 160까지의 배열을 만든뒤
그것을 저장하여
bins로 설정해주자
bins=
plt.hist( data=df, x='speed', rwidth=0.8, bins = my_bins )
plt.show()
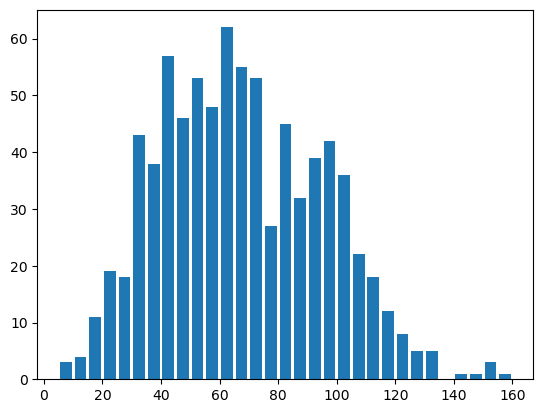
보다 정확한 형태로 알 수 있게 되었다


기본형과 가공한 그래프를 비교해보자
데이터를 가공하여야 하는 이유가 보이게 된다



