supervised는 y가 있었지만 unsupervised는 y가 없다
Clustering은 그룹화가 목적에 있다
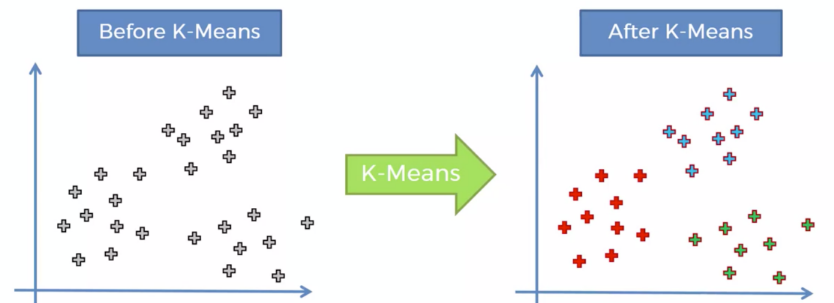
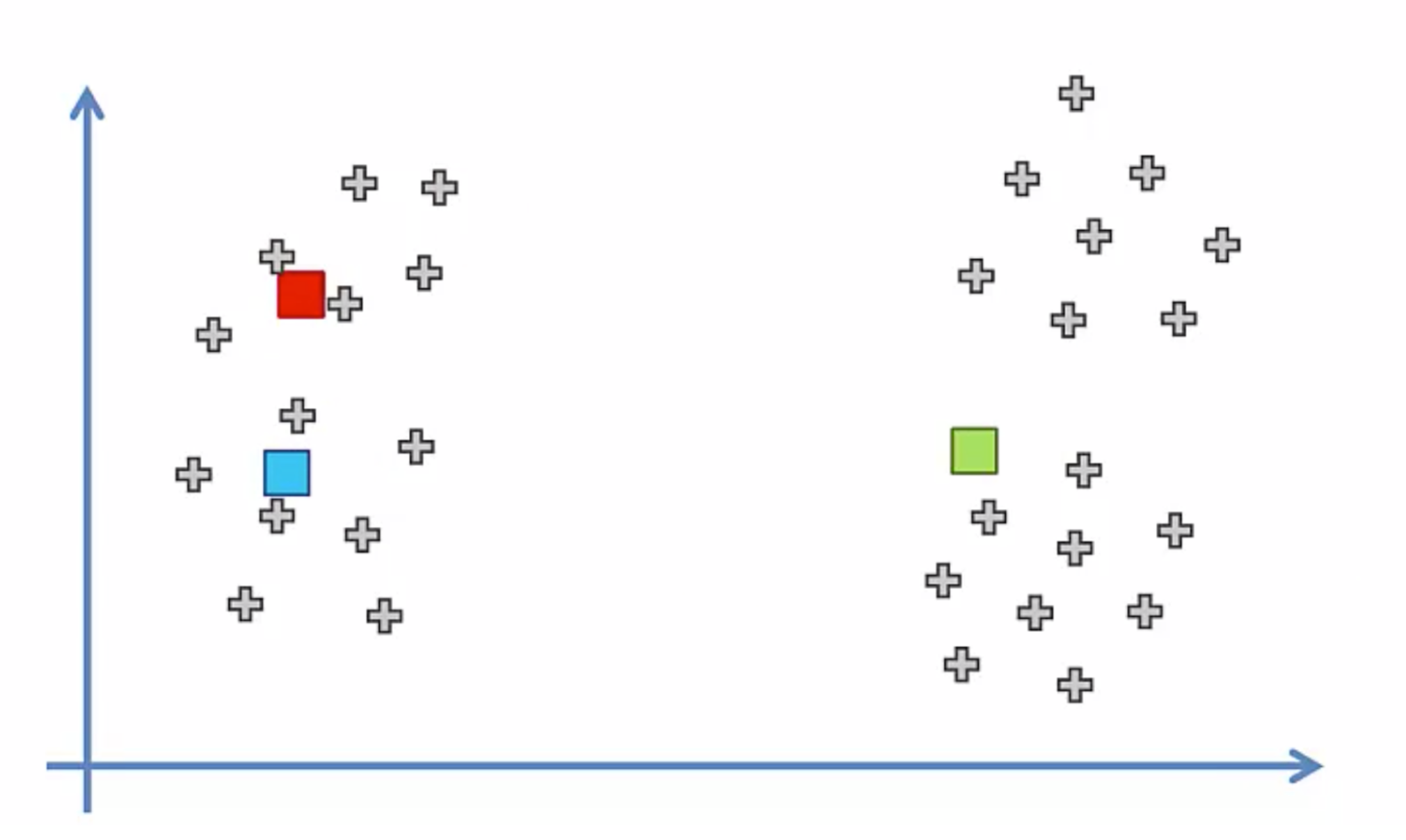
왼쪽같은 데이터들이 있을때
K-Means를 통해
3개의 그룹으로 나눌 수 있다
그리고
새로운 데이터가 들어왔을때
근접한 곳의 데이터로 들어가는것도 당연히 가능하겠다
그렇다면 어떻게 그룹이 나누어질까
우선 K-Means의 뜻부터 알고 가자
K는 상수 라는 뜻을 가지며 몇개의 그룹으로 나눌지에 대한 숫자이다
Means는 알다싶이 평균을 구하는것이고
그렇다면 몇개의 그룹으로 나누고 싶은지 입력하여
그룹마다의 평균을 구하여 각각의 그룹이 만들어지는것인데
그림을 보며 알아보자

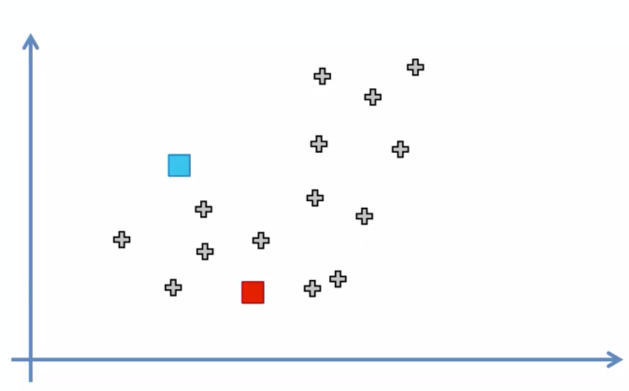
좌측의 그림처럼 데이터가 있을때 K에 2라는 숫자를 입력했을때
우측 그림처럼 랜덤한 위치에 두개의 점이 찍히며
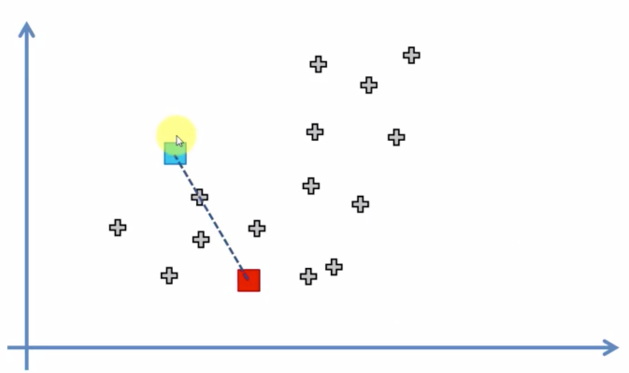

랜덤한 점 중앙을 직교하는 선을 그어

클러스터링, 즉 그룹화를 하고
그 그룹화 된 지역에서의 평균
즉 중심으로 점이 이동된다
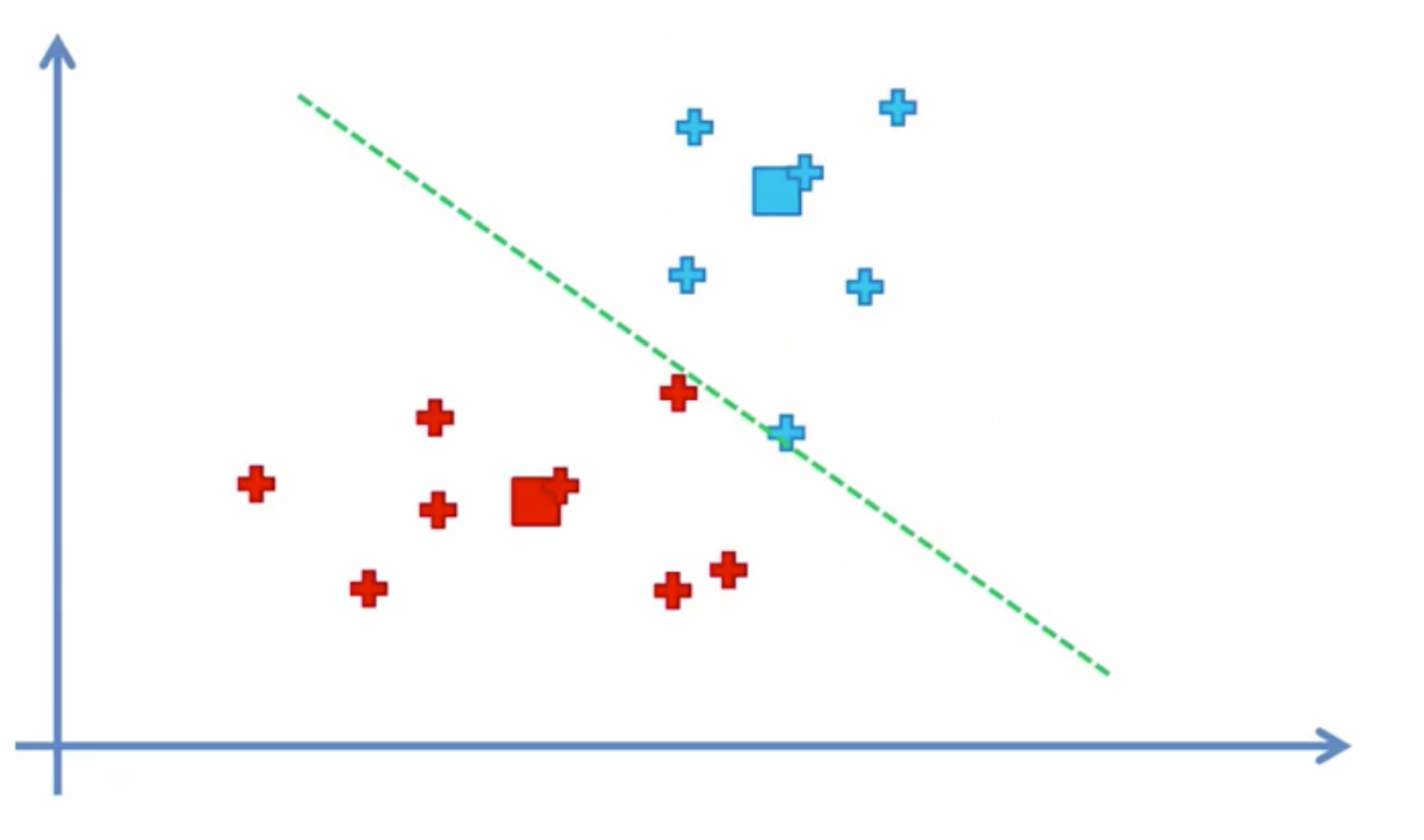
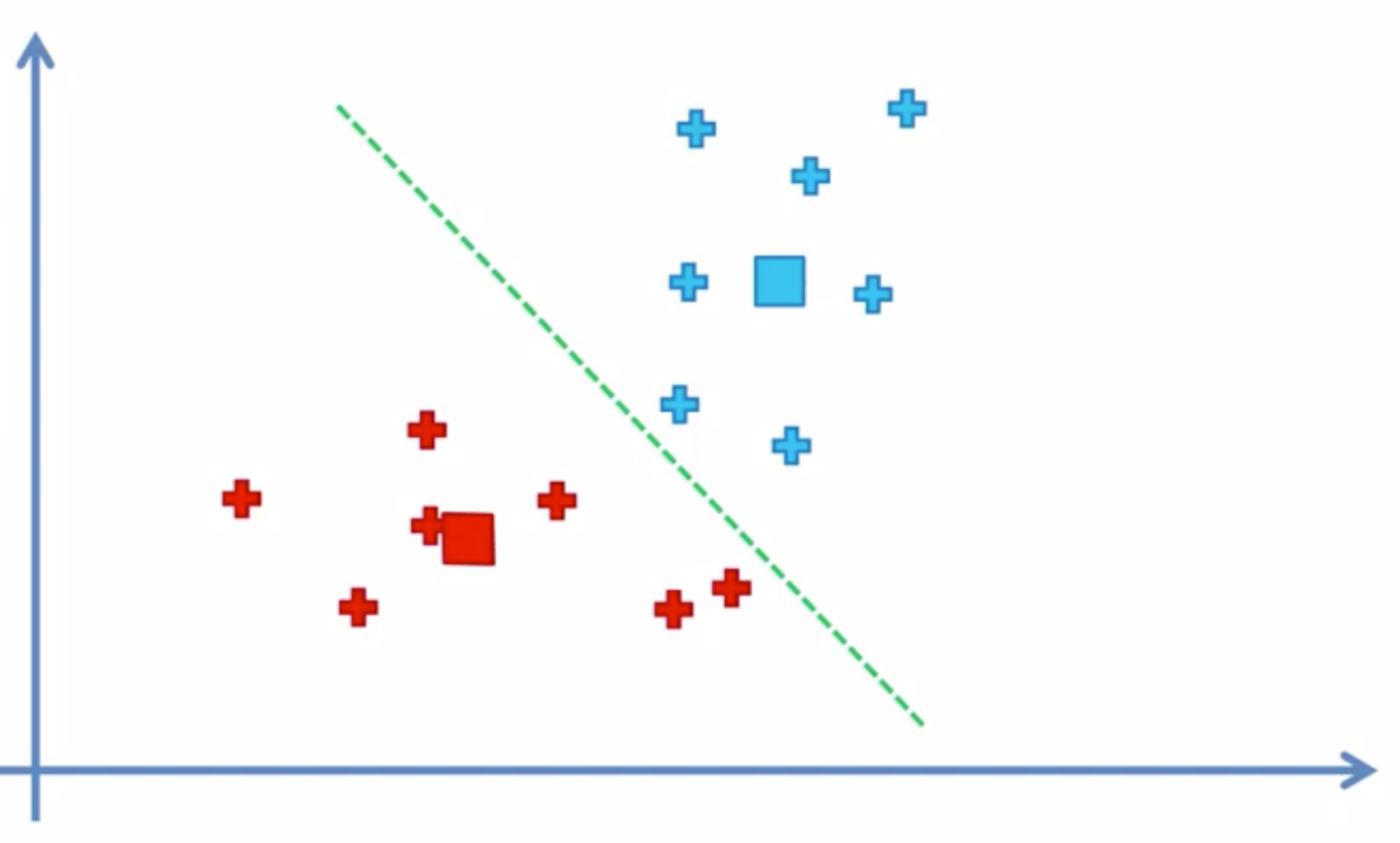
이것을 계속 반복하여 더 이상 그룹을 이동하는 데이터가 없을때
끝나게 된다
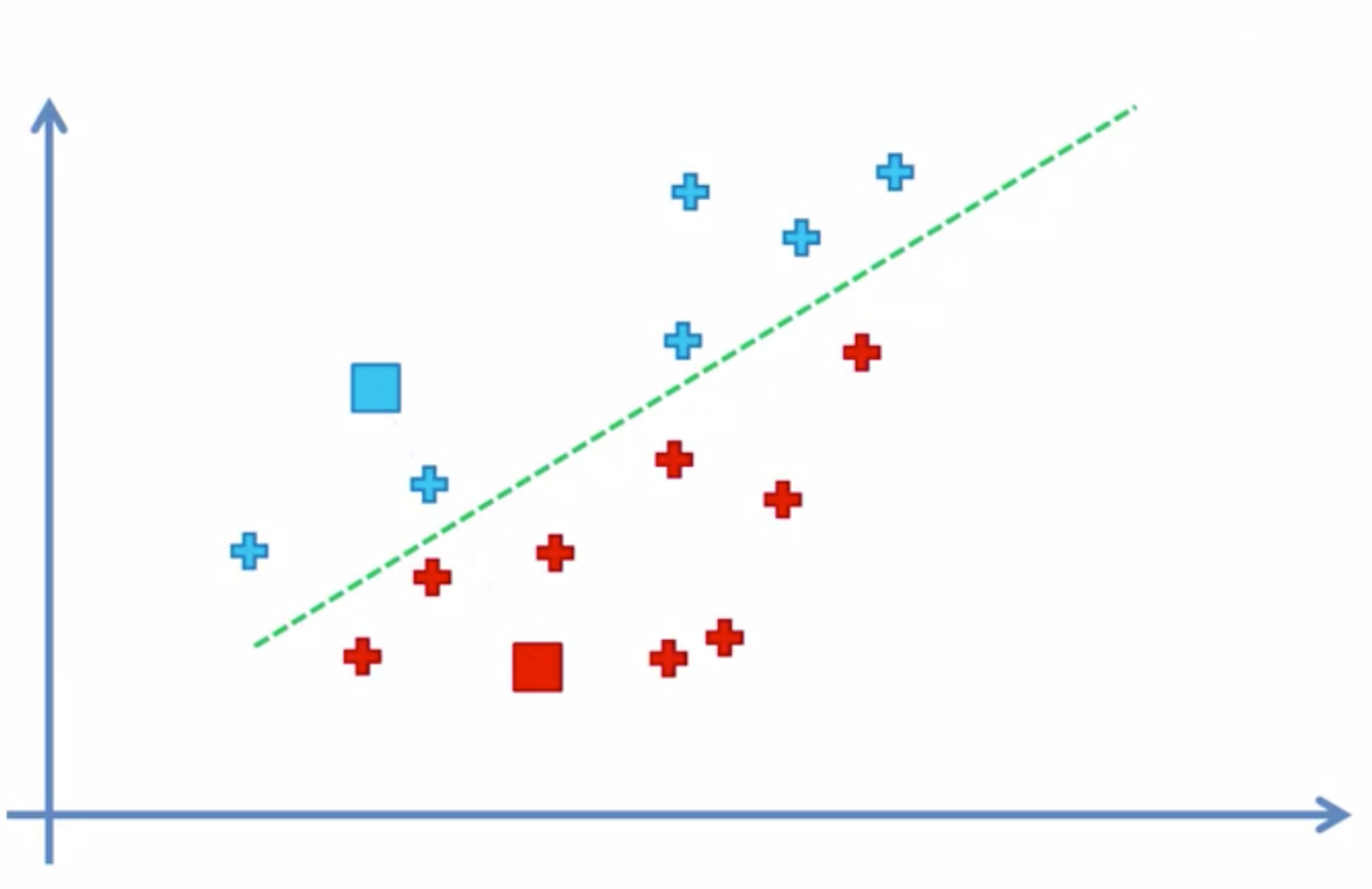
그러나 이 방법엔 문제가 있는데
바로 맨 처음 랜덤으로 점이 위치한다는것이다
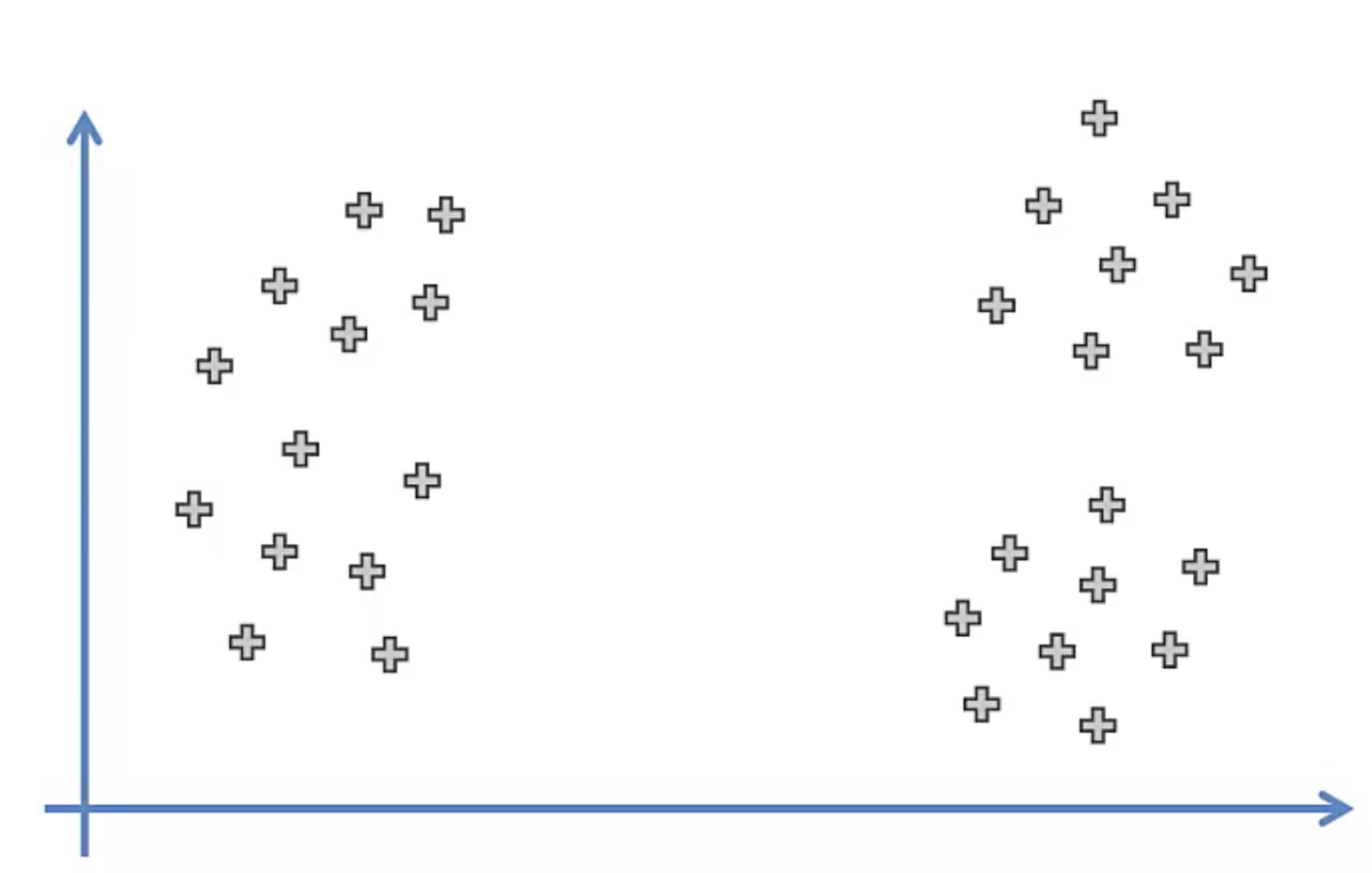
좌측의 데이터가 있을때 3개의 그룹으로 나눈다고 하면
우리가 원하는 모습은 우측의 모습일 것이다
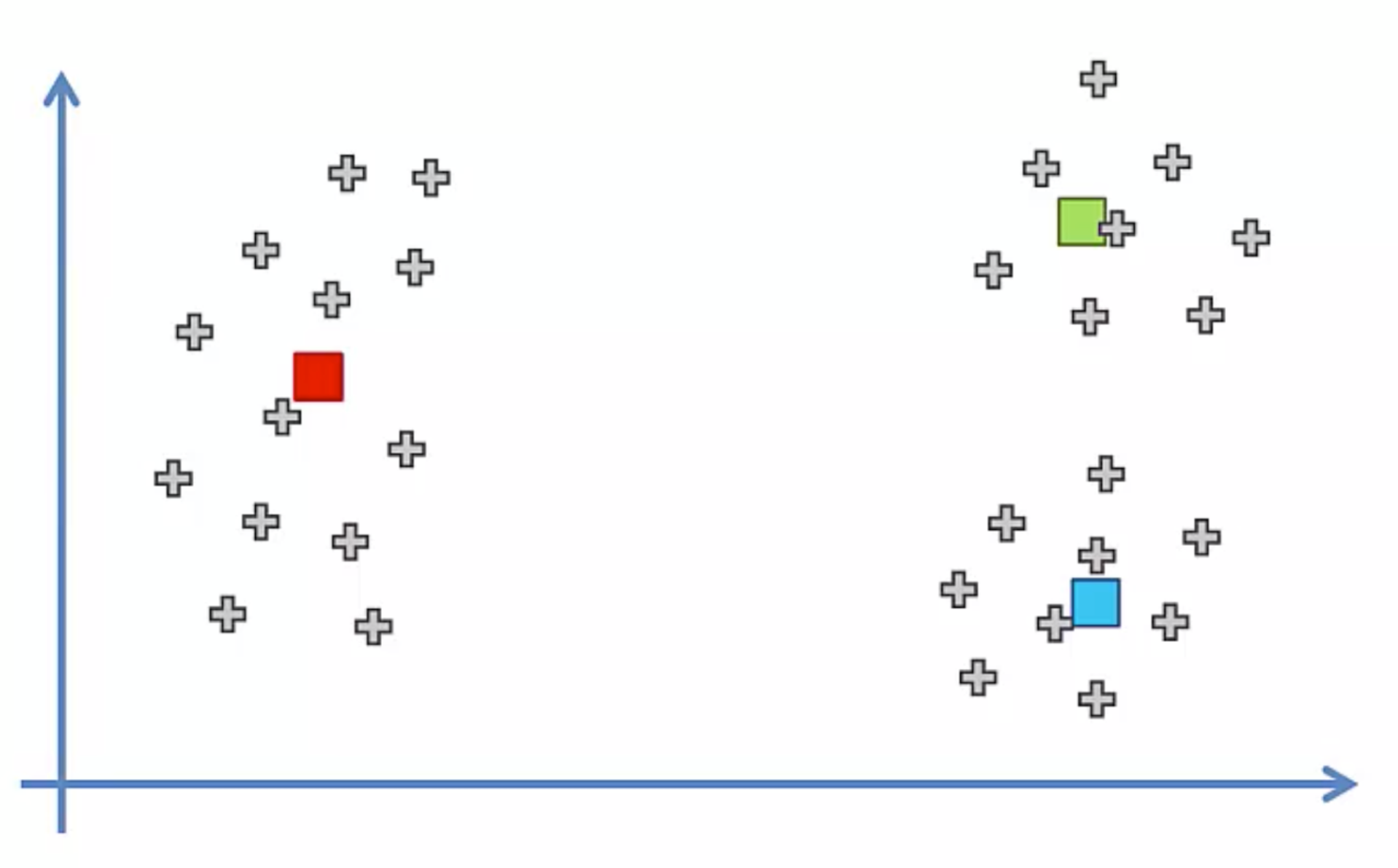
하지만
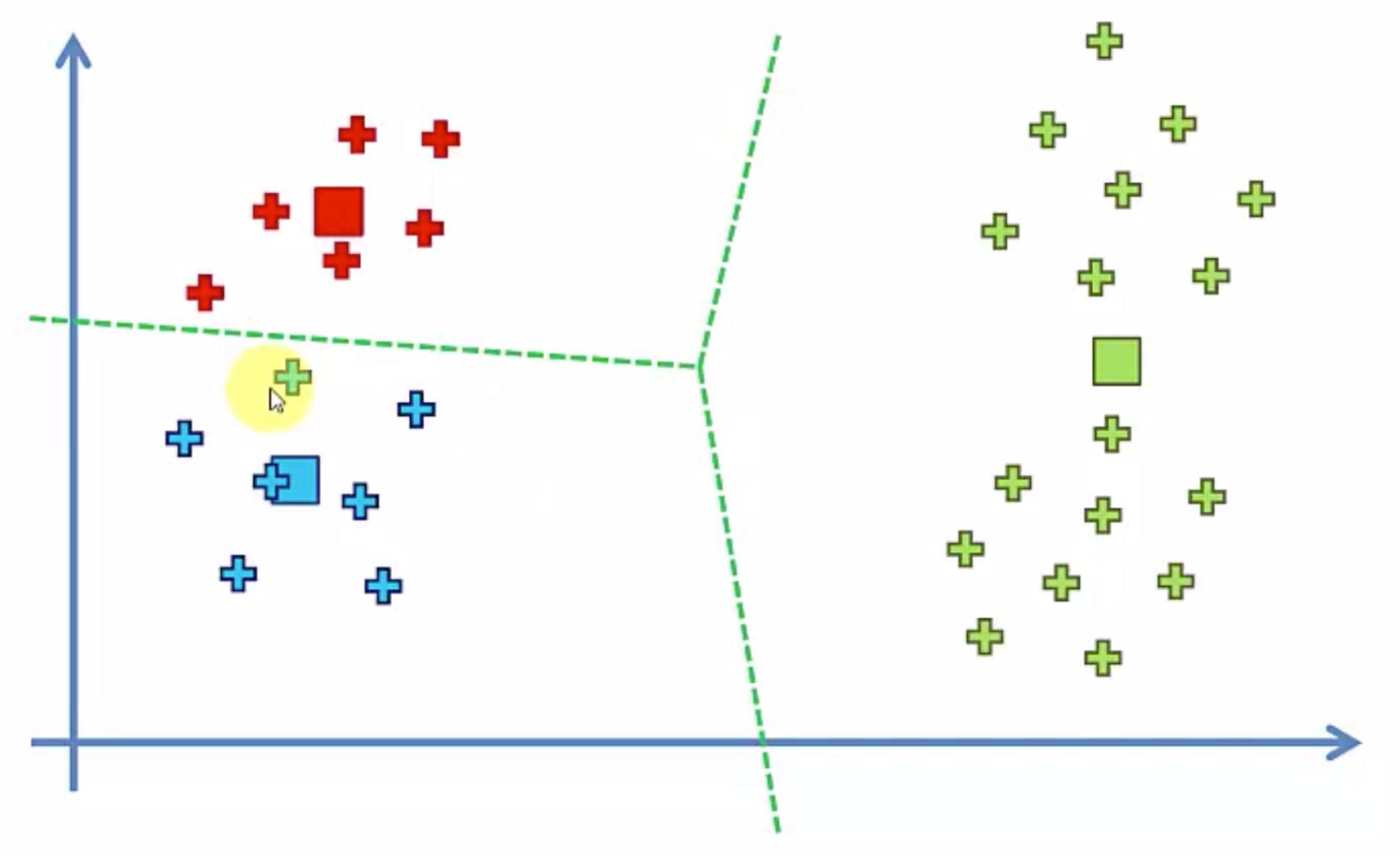
랜덤하는 점의 위치가 좌측같이 생겨버린다면
우측의 모습처럼 그룹이 만들어져버릴 것이다

이런 문제점을 해결한것이 K-Means++
우선 사용하기전에
사이킷런의 클러스터 모듈을 사용하여 KMeans를 임포트 해주자
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=3, random_state=10)
우선은 그룹화를 3으로 지정하고 해보자
y_pred = kmeans.fit_predict(X)
C:\ProgramData\anaconda3\Lib\site-packages\sklearn\cluster\_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(
C:\ProgramData\anaconda3\Lib\site-packages\sklearn\cluster\_kmeans.py:1382: UserWarning: KMeans is known to have a memory leak on Windows with MKL, when there are less chunks than available threads. You can avoid it by setting the environment variable OMP_NUM_THREADS=1.
warnings.warn(
y_pred
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 1, 2, 1, 2, 1, 2, 1,
2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1,
2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1,
2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1,
2, 1])df['Group'] = y_pred
df
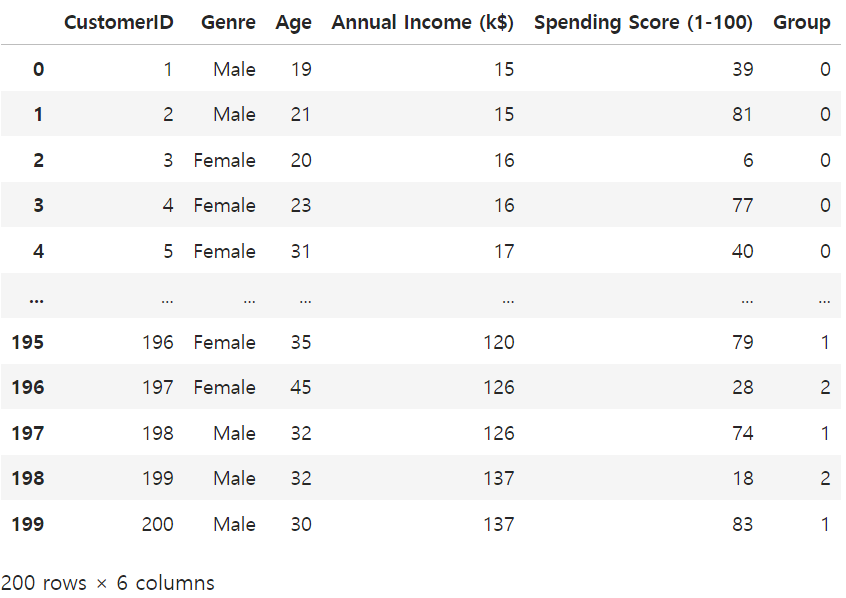
0,1,2로 그룹화가 진행된게 보여진다
그렇다면 몇개의 그룹으로 나누는것이 제일 효과가 좋을까?
wcss = []
for i in range(1, 10+1):
kmeans = KMeans(n_clusters = i , random_state=10)
kmeans.fit(X)
wcss.append( kmeans.inertia_ )1개의 그룹부터 10개까지의 그룹으로 만들어보자
wcss
[308862.06,
212889.442455243,
143391.59236035674,
104414.67534220166,
75399.61541401484,
58348.64136331505,
51167.19736842105,
45324.85021951262,
40811.455768566826,
37141.48254409704]
WCSS란 Within Cluster Sum of Squares
그룹이 얼마나 응집되어있나 알려주는 수치이다
중심에서 얼마나 가까운지를 표시한다
그러니 가까워질수록 뭉쳐있다는 뜻이고
가까워지는 폭이 줄어들수록 효과가 적다는 뜻
그 곳이 가장 K-Means 클러스터링의 효과가 좋은 곳이다
그래프로 표기하면 이렇다
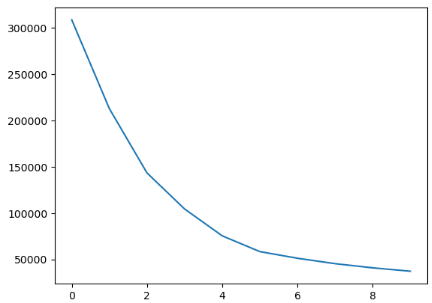

이러한 것을
팔꿈치모양과 비슷하다하여
엘보 메소드라고 하며
( ) 이 괄호안에 입력하는 것을 보통 파라미터라고 하고
n_cluster=
처럼
사람이 꼭 지정해줘야 하는 파라미터는
(디폴트값은 존재하지만 원하는 값을 찾기 위해 지정해줘야하는)
하이퍼 파리미터
Hyper parameter
라고 한다
'Python > MachineLearning' 카테고리의 다른 글
| Time Series Data forecasting Prophet (0) | 2024.04.19 |
|---|---|
| Hierarchical Clustering - 개념 (0) | 2024.04.16 |
| Decision Tree 의사결정 트리 - 개념 (0) | 2024.04.15 |
| Support Vector Machine - 개념 (0) | 2024.04.15 |
| K - Nearest Neighbor - 개념 (0) | 2024.04.15 |



