
피처스케일링이란
서로 다른 피처값의 범위(각각의 최대값, 각각의 최소값)등을 일치하도록 조정하는 작업이다
값의 범위가 데이터마다 다르면 인간조차도 해석이 쉽지 않은데
컴퓨터 또한 의미를 알지 못하기 때문에 하는것이 이롭고 해야만 한다
피처스케일링은
표준화와 정규화로 나뉘게 되는데
일반적으로 정규화가 더 많이 쓰인다
표준화 - Standardisation
공식은 어차피 컴퓨터가 알아서 할테니 자세히 알것까진 없고
표준편차와 평균을 중심으로 하는 스케일링 기법 이라는것까지만 알자
평균을 0으로 놓고 결과 분포에 따라 단위 표준편차를 사용한다
정규화 - Normalisation
마찬가지로 공식을 외울 필요는 없고
최소값과,최대값을 이용하여 0과 1 사이의 범위로 재조정시키는 스케일링 기법
이라는 정도만 기억하자
그렇기에 Min-Max Scaling 이라고도 한다
그렇다면 왜 일반적으로 정규화가 많이 쓰일까?
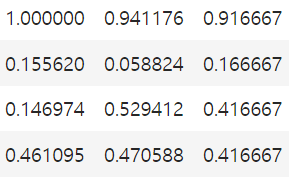
마치 백분율로 나온 듯한 숫자이기 때문일까
최대치가 1이라는걸 알기때문에 어느정도 가늠이 되기도 한다
'Python > MachineLearning' 카테고리의 다른 글
| Regression 1) .coef_ , .intercept_ , .predict( ) (0) | 2024.04.13 |
|---|---|
| Regression - Data Preprocessing (3) - StandardScaler(), MinMaxScaler(), train_test_split() (0) | 2024.04.13 |
| Regression - Data Preprocessing (2) 문자열의 데이터처리( Label Encoding, One Hot Encoding) (0) | 2024.04.13 |
| Regression - Data Preprocessing (1) - Nan처리, X와y의 데이터 분류 (0) | 2024.04.12 |
| 머신 러닝이란? - 기초 개념 (0) | 2024.04.12 |


