
국적과 나이, 그 사람의 연봉, 그 사람의 구매여부
라는 데이터가 있을때
각각의 국적별, 나이별, 연봉별, 구매여부별로 나누어서
데이터를 학습시켜
다른 데이터들이 들어왔을때 그 사람이 구매를 할지 안 할지를 예측해보자
1. NaN 처리
우선 맨 첫번째 단계는 NaN이 있는지 확인후 없다면 그대로 다음 단계로 넘어가고
있다면 삭제를 하든 데이터를 채워주든 해야할 것이다
df.isna().sum()
Country 0
Age 1
Salary 1
Purchased 0
dtype: int64
이렇게 된 경우에는 2가지 방법이 있다
1 - 1. 삭제하는 방법
df.dropna()
1 - 2. 채우는 방법
df.fillna(df.mean(numeric_only=True))
4번의 연봉, 6번의 나이가 해당 콜럼별의 평균값으로 들어갔다
일단 여기서는 삭제하는 방법으로 진행하겠다
** NaN이 0으로 바꾸어져 있을 경우 **
df.describe()
df.isna().sum()
Preg 0
Plas 0
Pres 0
skin 0
test 0
mass 0
pedi 0
age 0
class 0
dtype: int64데이터의 최소값이 0으로 나오는 이상한 컬럼들이 존재하는 경우
Nan을 0으로 채워넣은 것은 아닐까? (class는 값이 0과 1로만 존재하니 제외)
따라서 Plas컬럼부터 mass 컬럼까지는 0으로 셋팅되어있는 값을
NaN으로 만들어주자
df.loc[ : , 'Plas' : 'mass' ] = df.loc[ : , 'Plas' : 'mass' ].replace( 0 , np.nan )
df.isna().sum()
Preg 0
Plas 5
Pres 35
skin 227
test 374
mass 11
pedi 0
age 0
class 0
dtype: int64이후 위에서 배웠듯 삭제 혹은 채우는것을 선택하자
2. 훈련 시킬 데이터와 예측 값이 나올 데이터를 위해 X와 y로 데이터를 분류하라
y = df['Purchased']
X = df.loc[ : , 'Country' : 'Salary']
y는 결국 구매여부를 묻는 답이니 구매여부를 선택한다
X는 나머지 데이터들을 선택한다
데이터 불균형의 경우
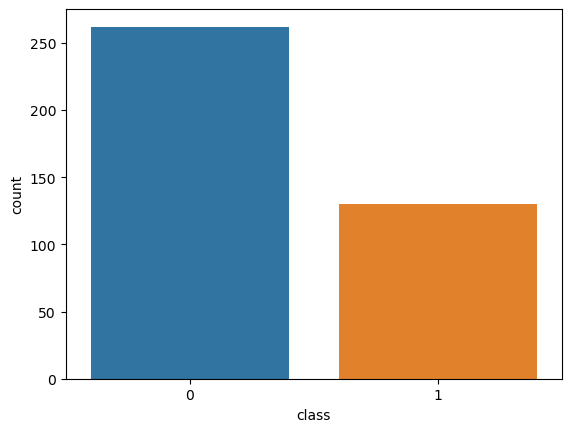
y.value_counts()
class
0 262
1 130
Name: count, dtype: int64sb.countplot(data = df, x='class')
plt.show()
pip install imblearn일단 설치 먼저 하고
from imblearn.over_sampling import SMOTE
임포트를 하여 사용해주면
sm = SMOTE(random_state=5)
X, y = sm.fit_resample(X,y)
X.shape
(524, 8)y.value_counts()
class
0 262
1 262
Name: count, dtype: int64
Regression - Data Preprocessing (2) 문자열의 데이터처리( Label Encoding, One Hot Encoding)
3. 문자열을 데이터로 처리 위에서 봤듯이 국적과 구매여부의 문자열은 컴퓨터가 이해하기 어려워한다 그러니 컴퓨터가 이해하기 쉬운 숫자로 변환시켜줘야 한다 레이블 인코딩과 원 핫 인코딩
hani08.tistory.com
Regression - Data Preprocessing (3) - StandardScaler(), MinMaxScaler(), train_test_split()
4. 데이터 표준화 - 피쳐스케일링 앞의 데이터를 무시하고도 나이의 최소값~최대값은 아무리 좋게 봐줘도 0~150을 넘길수가 없는 반면 연봉의 최소값~최대값의 크기는 데이터의 수치로만해도 40k~9
hani08.tistory.com
'Python > MachineLearning' 카테고리의 다른 글
| Regression 1) .coef_ , .intercept_ , .predict( ) (0) | 2024.04.13 |
|---|---|
| Regression - Data Preprocessing (3) - StandardScaler(), MinMaxScaler(), train_test_split() (0) | 2024.04.13 |
| Regression - Data Preprocessing (2) 문자열의 데이터처리( Label Encoding, One Hot Encoding) (0) | 2024.04.13 |
| 머신 러닝이란? - 기초 개념 (0) | 2024.04.12 |
| 피처스케일링 - 표준화(Standard), 정규화(MinMax) (0) | 2024.04.11 |


